Arroyo
Cloud-native stream processing with SQL, sub-second results
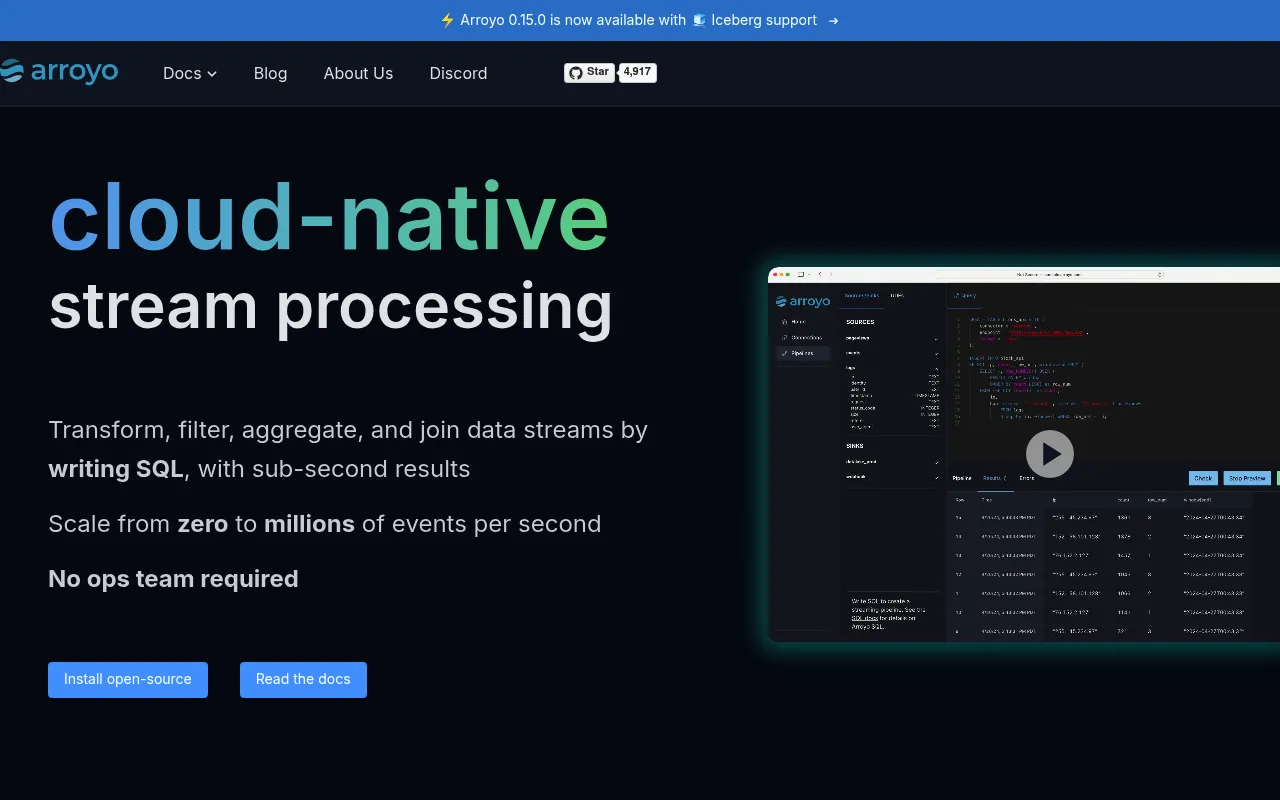
Arroyo is an open-source, cloud-native stream processing engine that lets users build real-time data pipelines using standard analytical SQL. Written in Rust and built around the Apache Arrow format, it delivers high performance and exactly-once semantics while scaling from zero to millions of events per second. It ships as a single binary and supports deployment via Docker, Kubernetes, or local development environments.
Users write standard analytical SQL queries that Arroyo compiles and executes as stateful streaming pipelines, with connectors for sources like Kafka and SSE and sinks for various data formats.
Data engineers and data scientists who need to process real-time data streams
Background.
- Status
- launched
- Business model
- open-source
- Launched
- Dec 2025
Similar projects.
Editorial take on the space this project sits in — momentum signals, adjacent moves, our call on whether the wedge is real. Get pinged when we publish a new read or when the landscape shifts.
Have a take on this space?
Tell us what you’d build differently, where you think the incumbents miss, or what we’ve gotten wrong about this project. Comments + reactions are coming soon.